
1. Introducción: ¿Qué es SQL?
SQL (Structured Query Language) es el lenguaje más utilizado para trabajar con bases de datos relacionales.
Se usa para:
- guardar información
- buscar datos
- relacionar tablas
- generar reportes
- analizar información
- y alimentar aplicaciones completas
Hoy en día, SQL está presente en:
- ecommerce
- ERPs
- dashboards
- sistemas administrativos
- apps móviles
- redes sociales
- videojuegos
- plataformas financieras
- y prácticamente cualquier sistema que maneje datos
SQL no se usa de una sola forma
Dependiendo del perfil profesional, SQL suele entenderse de maneras distintas.
| Perfil | Cómo suele ver SQL |
|---|---|
| Desarrollador | Memoria persistente del sistema |
| Administrativo | Excel relacional |
| Analista | Herramienta de reporting |
| Data engineer | Pipeline de transformación |
| Negocio/ERP | Historial y control operativo |
Por eso SQL puede sentirse muy diferente según el contexto en el que se utilice.
Entonces… ¿qué hace realmente SQL?
La idea principal de SQL es trabajar con tablas.
Con SQL puedes:
- filtrar información
- ordenar resultados
- combinar tablas
- agrupar datos
- calcular métricas
- transformar información
- y construir consultas más complejas
Por ejemplo:
SELECT nombre, precio
FROM productos
WHERE precio > 100;
Esta consulta:
- toma datos de una tabla
- filtra productos con precio mayor a 100
- y devuelve únicamente ciertas columnas
Cómo pensar en SQL
Una de las ideas más importantes para aprender SQL es esta:
SQL transforma tablas.
Casi todo lo que harás consistirá en:
- seleccionar filas
- elegir columnas
- combinar información
- o generar nuevas vistas de los datos existentes
Mientras más rápido desarrolles esa intuición, más natural empezará a sentirse SQL.
2. El modelo relacional: cómo pensar en tablas
Las bases de datos relacionales organizan la información en tablas.
Cada tabla representa un tipo de entidad del mundo real:
| Tabla | Representa |
|---|---|
clientes | Personas que compran |
productos | Artículos disponibles |
pedidos | Compras realizadas |
empleados | Personal de la empresa |
Filas y columnas
Cada tabla está formada por:
- columnas → describen atributos
- filas → representan registros individuales
Por ejemplo:
Tabla productos
| id | nombre | precio | stock |
|---|---|---|---|
| 1 | Mouse Gamer | 599 | 12 |
| 2 | Teclado Mecánico | 1299 | 5 |
| 3 | Monitor 24″ | 3499 | 8 |
Aquí:
nombre,precioystockson columnas- cada producto individual es una fila
Claves primarias (Primary Key)
Normalmente cada fila necesita un identificador único.
A esto se le llama:
clave primaria o
PRIMARY KEY.
Por ejemplo:
| id | nombre |
|---|---|
| 1 | Juan |
| 2 | Ana |
| 3 | Carlos |
La columna id permite identificar cada registro de manera única.
Relaciones entre tablas
La verdadera fuerza de SQL aparece cuando las tablas se conectan entre sí.
Por ejemplo:
Tabla clientes
| id | nombre |
|---|---|
| 1 | Juan |
| 2 | Ana |
Tabla pedidos
| id | cliente_id | total |
|---|---|---|
| 101 | 1 | 2500 |
| 102 | 2 | 899 |
La columna cliente_id relaciona cada pedido con un cliente.
Eso permite responder preguntas como:
- ¿qué pedidos hizo cada cliente?
- ¿cuánto ha comprado un usuario?
- ¿qué clientes nunca han comprado?
Relaciones comunes
Uno a muchos (1:N)
Un cliente puede tener muchos pedidos.
cliente → pedidos
Es la relación más común.
Muchos a muchos (N:M)
Un pedido puede contener muchos productos, y un producto puede aparecer en muchos pedidos.
pedidos ↔ productos
Normalmente esto se resuelve usando una tabla intermedia.
3. Nuestro conjunto de datos de ejemplo
Para mantener todos los ejemplos conectados y fáciles de seguir, durante esta guía utilizaremos un pequeño sistema de ecommerce ficticio.
La idea es trabajar siempre sobre el mismo universo de datos para que las consultas tengan continuidad y sea más fácil entender cómo se relacionan las tablas.
Las tablas principales
| Tabla | Descripción |
|---|---|
clientes | Usuarios registrados |
productos | Artículos disponibles |
categorias | Clasificación de productos |
pedidos | Compras realizadas |
detalle_pedido | Productos incluidos en cada pedido |
Relación entre tablas
clientes
│
└── pedidos
│
└── detalle_pedido
│
└── productos
│
└── categorias
Tabla clientes
| id | nombre | |
|---|---|---|
| 1 | Juan Pérez | juan@email.com |
| 2 | Ana López | ana@email.com |
| 3 | Carlos Ruiz | carlos@email.com |
Tabla categorias
| id | nombre |
|---|---|
| 1 | Electrónica |
| 2 | Oficina |
| 3 | Accesorios |
Tabla productos
| id | nombre | categoria_id | precio | stock |
|---|---|---|---|---|
| 1 | Mouse Gamer | 1 | 599 | 12 |
| 2 | Teclado Mecánico | 1 | 1299 | 5 |
| 3 | Libreta A5 | 2 | 89 | 40 |
| 4 | Cable USB-C | 3 | 199 | 25 |
Tabla pedidos
| id | cliente_id | fecha | total |
|---|---|---|---|
| 101 | 1 | 2026-05-01 | 1898 |
| 102 | 2 | 2026-05-02 | 288 |
| 103 | 1 | 2026-05-04 | 199 |
Tabla detalle_pedido
| pedido_id | producto_id | cantidad |
|---|---|---|
| 101 | 1 | 1 |
| 101 | 2 | 1 |
| 102 | 3 | 1 |
| 102 | 4 | 1 |
| 103 | 4 | 1 |
Lo que construiremos con estas tablas
Con este pequeño dataset podremos aprender:
- CRUD básico
- filtros y búsquedas
- paginación
- JOINs
- agrupaciones
- rankings
- subconsultas
- vistas
- y análisis más avanzados
Aunque el sistema es pequeño, representa muchos de los patrones reales que aparecen en aplicaciones modernas.
4. Tipos de datos y creación de tablas
Antes de guardar información en una base de datos, necesitamos definir:
- qué tipo de información almacenaremos,
- cómo se relaciona,
- y qué reglas debe cumplir.
A esto se le conoce como:
modelar datos.
Tipos de datos más comunes
Cada columna de una tabla tiene un tipo de dato.
Ese tipo define qué clase de información puede almacenarse.
| Tipo | Uso común |
|---|---|
INTEGER | Números enteros |
NUMERIC | Decimales y cantidades monetarias |
TEXT | Texto largo o variable |
VARCHAR(n) | Texto con longitud máxima |
BOOLEAN | Verdadero o falso |
DATE | Fechas |
TIMESTAMP | Fecha y hora |
Ejemplo práctico
Tabla productos
| columna | tipo |
|---|---|
id | INTEGER |
nombre | TEXT |
precio | NUMERIC |
stock | INTEGER |
Crear tablas con SQL
Las tablas se crean usando CREATE TABLE.
Por ejemplo:
CREATE TABLE productos (
id INTEGER PRIMARY KEY,
nombre TEXT NOT NULL,
precio NUMERIC(10,2),
stock INTEGER
);
¿Qué significa cada parte?
| Elemento | Descripción |
|---|---|
id INTEGER | Columna numérica |
PRIMARY KEY | Identificador único |
nombre TEXT | Texto variable |
NOT NULL | Campo obligatorio |
NUMERIC(10,2) | Número decimal con precisión |
Restricciones básicas (Constraints)
Las restricciones ayudan a mantener los datos limpios y consistentes.
PRIMARY KEY
Identifica cada fila de forma única.
id INTEGER PRIMARY KEY
NOT NULL
Impide valores vacíos.
nombre TEXT NOT NULL
UNIQUE
Evita valores repetidos.
email TEXT UNIQUE
DEFAULT
Asigna un valor automático si no se especifica uno.
stock INTEGER DEFAULT 0
FOREIGN KEY
Conecta una tabla con otra.
cliente_id INTEGER REFERENCES clientes(id)
Esto permite relacionar información entre tablas.
Ejemplo completo
CREATE TABLE pedidos (
id INTEGER PRIMARY KEY,
cliente_id INTEGER REFERENCES clientes(id),
fecha DATE,
total NUMERIC(10,2)
);
Diseñar tablas también es diseñar reglas
Las bases de datos no solo almacenan información.
También ayudan a protegerla.
Por ejemplo:
- impedir IDs duplicados
- evitar pedidos sin cliente
- bloquear valores inválidos
- mantener relaciones consistentes
Mientras mejor esté diseñado el modelo de datos, más fácil será consultar y mantener el sistema después.
5. Operaciones básicas con datos (CRUD)
Una vez creadas las tablas, el siguiente paso es trabajar con la información.
Las operaciones más básicas en SQL suelen conocerse como:
| Operación | Significado |
|---|---|
| CREATE | Crear información |
| READ | Consultar datos |
| UPDATE | Modificar registros |
| DELETE | Eliminar información |
A este conjunto normalmente se le conoce como:
CRUD.
INSERT: agregar información
Para insertar nuevos registros usamos INSERT INTO.
Ejemplo
INSERT INTO productos (id, nombre, precio, stock)
VALUES (1, 'Mouse Gamer', 599, 12);
Resultado esperado
Tabla productos
| id | nombre | precio | stock |
|---|---|---|---|
| 1 | Mouse Gamer | 599 | 12 |
INSERT con múltiples filas
También es posible insertar varios registros al mismo tiempo.
INSERT INTO productos (id, nombre, precio, stock)
VALUES
(2, 'Teclado Mecánico', 1299, 5),
(3, 'Libreta A5', 89, 40),
(4, 'Cable USB-C', 199, 25);
SELECT: consultar información
SELECT es probablemente el comando más utilizado de SQL.
Permite recuperar información desde una tabla.
Consultar todas las columnas
SELECT *
FROM productos;
Resultado
| id | nombre | precio | stock |
|---|---|---|---|
| 1 | Mouse Gamer | 599 | 12 |
| 2 | Teclado Mecánico | 1299 | 5 |
| 3 | Libreta A5 | 89 | 40 |
| 4 | Cable USB-C | 199 | 25 |
Consultar columnas específicas
SELECT nombre, precio
FROM productos;
Resultado
| nombre | precio |
|---|---|
| Mouse Gamer | 599 |
| Teclado Mecánico | 1299 |
| Libreta A5 | 89 |
| Cable USB-C | 199 |
UPDATE: modificar información
Para actualizar registros usamos UPDATE.
Ejemplo
UPDATE productos
SET precio = 649
WHERE id = 1;
Antes
| id | nombre | precio |
|---|---|---|
| 1 | Mouse Gamer | 599 |
Después
| id | nombre | precio |
|---|---|---|
| 1 | Mouse Gamer | 649 |
IMPORTANTE: usar WHERE
Sin WHERE, el cambio afectará todas las filas de la tabla.
UPDATE productos
SET stock = 0;
Esto modificaría todos los productos.
DELETE: eliminar registros
Para borrar información usamos DELETE.
Ejemplo
DELETE FROM productos
WHERE id = 4;
Antes
| id | nombre |
|---|---|
| 4 | Cable USB-C |
Después
El registro desaparece de la tabla.
IMPORTANTE: DELETE también usa WHERE
Si omites WHERE, se eliminarán todas las filas.
DELETE FROM productos;
La tabla seguirá existiendo, pero vacía.
CRUD en la vida real
Estas operaciones aparecen constantemente en aplicaciones reales:
| Acción del usuario | Operación SQL |
|---|---|
| Crear cuenta | INSERT |
| Ver productos | SELECT |
| Editar perfil | UPDATE |
| Cancelar registro | DELETE |
Prácticamente cualquier sistema moderno utiliza CRUD continuamente detrás de escena.
6. Filtrado, búsqueda y paginación
Una de las tareas más comunes en SQL es encontrar exactamente la información que necesitamos.
Para eso existen herramientas como:
- filtros
- búsquedas parciales
- ordenamiento
- y paginación
Estas operaciones aparecen constantemente en:
- ecommerce
- dashboards
- ERPs
- sistemas administrativos
- APIs
- y motores de búsqueda internos
Filtrar información con WHERE
La cláusula WHERE permite seleccionar únicamente las filas que cumplen una condición.
Ejemplo
SELECT *
FROM productos
WHERE precio > 500;
Resultado
| id | nombre | precio |
|---|---|---|
| 1 | Mouse Gamer | 599 |
| 2 | Teclado Mecánico | 1299 |
Operadores comunes
| Operador | Significado |
|---|---|
= | Igual |
!= | Diferente |
> | Mayor que |
< | Menor que |
>= | Mayor o igual |
<= | Menor o igual |
Combinar condiciones
AND
Todas las condiciones deben cumplirse.
SELECT *
FROM productos
WHERE precio > 100
AND stock > 10;
OR
Se cumple al menos una condición.
SELECT *
FROM productos
WHERE stock < 5
OR precio > 1000;
Filtrar múltiples valores con IN
SELECT *
FROM productos
WHERE id IN (1, 3, 4);
Filtrar rangos con BETWEEN
SELECT *
FROM productos
WHERE precio BETWEEN 100 AND 1000;
Buscar texto parcialmente con LIKE
LIKE permite realizar búsquedas parciales.
Ejemplo
SELECT *
FROM productos
WHERE nombre LIKE '%Mouse%';
¿Qué significa %?
El símbolo % funciona como comodín.
| Patrón | Significado |
|---|---|
'Mouse%' | Empieza con «Mouse» |
'%Mouse' | Termina con «Mouse» |
'%Mouse%' | Contiene «Mouse» |
Búsquedas sin distinguir mayúsculas
En PostgreSQL existe ILIKE.
SELECT *
FROM productos
WHERE nombre ILIKE '%teclado%';
Esto encuentra:
Teclado,TECLADO,teclado,TeClAdO.
Ordenar resultados con ORDER BY
Ascendente
SELECT nombre, precio
FROM productos
ORDER BY precio ASC;
Descendente
SELECT nombre, precio
FROM productos
ORDER BY precio DESC;
Resultado descendente
| nombre | precio |
|---|---|
| Teclado Mecánico | 1299 |
| Mouse Gamer | 599 |
| Cable USB-C | 199 |
| Libreta A5 | 89 |
Limitar resultados con LIMIT
SELECT *
FROM productos
LIMIT 2;
Resultado
| id | nombre |
|---|---|
| 1 | Mouse Gamer |
| 2 | Teclado Mecánico |
Paginar resultados con OFFSET
OFFSET permite saltar filas.
SELECT *
FROM productos
LIMIT 2 OFFSET 2;
Resultado
| id | nombre |
|---|---|
| 3 | Libreta A5 |
| 4 | Cable USB-C |
¿Por qué importa la paginación?
La paginación aparece constantemente en aplicaciones reales:
- catálogos de productos,
- tablas administrativas,
- APIs,
- dashboards,
- redes sociales,
- resultados de búsqueda.
Sin paginación, una consulta podría intentar devolver miles o millones de filas al mismo tiempo.
Cómo pensar esta sección
Hasta ahora, SQL ya puede:
- guardar información,
- modificar registros,
- eliminar datos,
- filtrar resultados,
- ordenar información,
- buscar coincidencias parciales,
- y dividir resultados en páginas.
Ya empezamos a pasar de:
“almacenar datos”
a:
“explorar y recuperar información útil”.
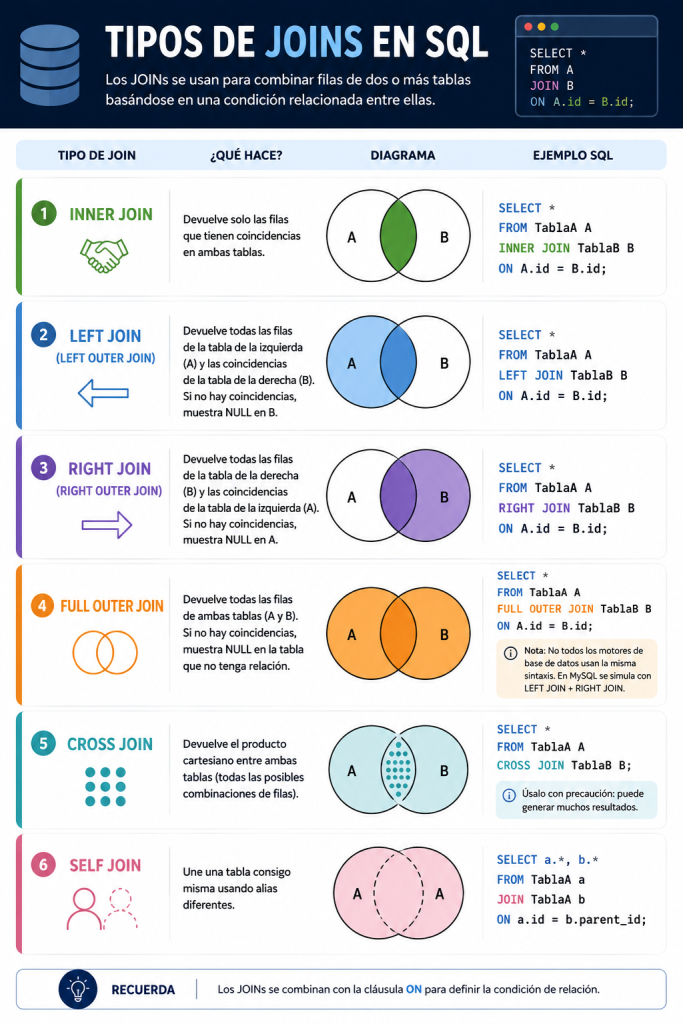
7. JOINs: combinando información entre tablas
Hasta ahora hemos trabajado con tablas individuales.
Pero una de las mayores fortalezas de SQL es poder relacionar información entre múltiples tablas.
Aquí es donde SQL realmente empieza a sentirse poderoso.
El problema
Supongamos que tenemos estas tablas:
Tabla clientes
| id | nombre |
|---|---|
| 1 | Juan Pérez |
| 2 | Ana López |
Tabla pedidos
| id | cliente_id | total |
|---|---|---|
| 101 | 1 | 1898 |
| 102 | 2 | 288 |
| 103 | 1 | 199 |
La tabla pedidos no guarda el nombre del cliente.
Solo almacena:
cliente_id
Ese valor funciona como referencia hacia la tabla clientes.
Entonces… ¿cómo obtenemos el nombre del cliente?
Aquí es donde aparece JOIN.
INNER JOIN
INNER JOIN combina filas cuando existe coincidencia entre ambas tablas.
Ejemplo
SELECT
pedidos.id,
clientes.nombre,
pedidos.total
FROM pedidos
INNER JOIN clientes
ON pedidos.cliente_id = clientes.id;
Resultado
| pedido | nombre | total |
|---|---|---|
| 101 | Juan Pérez | 1898 |
| 102 | Ana López | 288 |
| 103 | Juan Pérez | 199 |
Cómo leer un JOIN mentalmente
“Une pedidos con clientes
cuando cliente_id coincida con id”
¿Qué hace ON?
La cláusula ON define la condición de unión.
ON pedidos.cliente_id = clientes.id
Esto significa:
- toma el
cliente_iddel pedido, - búscalo en
clientes.id, - y combina las filas cuando coincidan.
Visualmente
pedidos.cliente_id → clientes.id
LEFT JOIN
LEFT JOIN devuelve:
- todas las filas de la tabla izquierda,
- incluso si no existe coincidencia en la derecha.
Ejemplo
Tabla clientes
| id | nombre |
|---|---|
| 1 | Juan Pérez |
| 2 | Ana López |
| 3 | Carlos Ruiz |
Tabla pedidos
| id | cliente_id |
|---|---|
| 101 | 1 |
| 102 | 2 |
Consulta
SELECT
clientes.nombre,
pedidos.id AS pedido_id
FROM clientes
LEFT JOIN pedidos
ON clientes.id = pedidos.cliente_id;
Resultado
| nombre | pedido_id |
|---|---|
| Juan Pérez | 101 |
| Ana López | 102 |
| Carlos Ruiz | NULL |
¿Qué significa NULL aquí?
Significa:
“no hubo coincidencia”.
Carlos existe como cliente, pero todavía no tiene pedidos.
RIGHT JOIN
RIGHT JOIN funciona igual que LEFT JOIN, pero priorizando la tabla derecha.
En la práctica, muchas personas prefieren usar LEFT JOIN para mantener las consultas más fáciles de leer.
FULL OUTER JOIN
FULL OUTER JOIN devuelve:
- todas las filas de ambas tablas,
- incluso cuando no hay coincidencias.
CROSS JOIN
CROSS JOIN genera todas las combinaciones posibles entre dos tablas.
Ejemplo
SELECT *
FROM productos
CROSS JOIN categorias;
Si hay:
- 4 productos,
- y 3 categorías,
el resultado tendrá:
4 × 3 = 12 filas
SELF JOIN
Un SELF JOIN ocurre cuando una tabla se une consigo misma.
Esto suele utilizarse en:
- jerarquías,
- organigramas,
- categorías anidadas,
- estructuras padre-hijo.
Ejemplo conceptual
Tabla empleados
| id | nombre | jefe_id |
|---|---|---|
| 1 | Laura | NULL |
| 2 | Pedro | 1 |
| 3 | Ana | 1 |
Aquí:
- Laura es jefa,
- Pedro y Ana dependen de Laura.
Consulta
SELECT
e.nombre AS empleado,
j.nombre AS jefe
FROM empleados e
LEFT JOIN empleados j
ON e.jefe_id = j.id;
Resultado
| empleado | jefe |
|---|---|
| Laura | NULL |
| Pedro | Laura |
| Ana | Laura |
El error más común con JOINs
Muchos principiantes intentan memorizar JOINs.
Eso suele terminar en confusión.
La forma correcta de pensar un JOIN es:
“Estoy conectando información relacionada entre tablas”.
No es magia. No es sintaxis rara. Es simplemente relacionar datos que comparten una referencia común.
Cómo pensar en JOINs
Los JOINs aparecen en prácticamente cualquier sistema real:
| Problema | JOIN involucrado |
|---|---|
| Ver pedidos con nombres de clientes | pedidos + clientes |
| Mostrar productos por categoría | productos + categorias |
| Ver detalle de una compra | pedidos + detalle_pedido |
| Obtener historial de un usuario | usuarios + acciones |
Sin JOINs, las bases de datos relacionales perderían gran parte de su poder.
8. Agrupación y transformación de información
Hasta ahora hemos trabajado principalmente con filas individuales.
Pero SQL también puede ayudarnos a:
- resumir información,
- calcular métricas,
- agrupar datos,
- generar estadísticas,
- y transformar tablas completas en reportes útiles.
Aquí es donde SQL empieza a sentirse mucho más analítico.
Funciones de agregación
Las funciones de agregación toman múltiples filas y generan un único resultado.
| Función | Descripción |
|---|---|
COUNT() | Cuenta filas |
SUM() | Suma valores |
AVG() | Calcula promedio |
MIN() | Obtiene el valor mínimo |
MAX() | Obtiene el valor máximo |
COUNT()
Contar productos
SELECT COUNT(*)
FROM productos;
Resultado
| count |
|---|
| 4 |
SUM()
Sumar inventario total
SELECT SUM(stock)
FROM productos;
Resultado
| sum |
|---|
| 82 |
AVG()
Precio promedio
SELECT AVG(precio)
FROM productos;
GROUP BY
GROUP BY permite agrupar filas que comparten un mismo valor.
Es una de las herramientas más importantes de SQL para reporting y análisis.
Ejemplo
Productos agrupados por categoría
SELECT
categoria_id,
COUNT(*) AS total_productos
FROM productos
GROUP BY categoria_id;
Resultado
| categoria_id | total_productos |
|---|---|
| 1 | 2 |
| 2 | 1 |
| 3 | 1 |
¿Qué está pasando aquí?
SQL:
- agrupa productos por categoría,
- junta las filas similares,
- y luego calcula el total de cada grupo.
GROUP BY + SUM
Total vendido por cliente
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id;
Resultado
| cliente_id | total_gastado |
|---|---|
| 1 | 2097 |
| 2 | 288 |
Renombrar columnas con AS
AS permite dar nombres más claros a los resultados.
SELECT
AVG(precio) AS precio_promedio
FROM productos;
Filtrar grupos con HAVING
WHERE filtra filas.
HAVING filtra grupos después del GROUP BY.
Ejemplo
Clientes con compras mayores a 1000
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
HAVING SUM(total) > 1000;
Resultado
| cliente_id | total_gastado |
|---|---|
| 1 | 2097 |
CASE WHEN
CASE WHEN funciona como una estructura condicional dentro de SQL.
Permite generar valores distintos dependiendo de una condición.
Ejemplo
Clasificar productos según precio
SELECT
nombre,
precio,
CASE
WHEN precio >= 1000 THEN 'Premium'
WHEN precio >= 500 THEN 'Media'
ELSE 'Económica'
END AS categoria_precio
FROM productos;
Resultado
| nombre | precio | categoria_precio |
|---|---|---|
| Mouse Gamer | 599 | Media |
| Teclado Mecánico | 1299 | Premium |
| Libreta A5 | 89 | Económica |
DISTINCT
DISTINCT elimina valores repetidos.
Categorías únicas
SELECT DISTINCT categoria_id
FROM productos;
Resultado
| categoria_id |
|---|
| 1 |
| 2 |
| 3 |
Cómo pensar esta sección
Hasta ahora SQL ya puede:
- recuperar información,
- relacionar tablas,
- filtrar datos,
- agrupar registros,
- calcular métricas,
- y transformar resultados.
En este punto, SQL deja de sentirse solamente como:
“un lugar donde guardar datos”
y empieza a parecerse más a:
“una herramienta para analizar información”.
9. Subconsultas: consultas dentro de consultas
En SQL, una consulta también puede utilizar el resultado de otra consulta.
A esto se le conoce como:
subconsulta o subquery.
Las subconsultas permiten:
- reutilizar resultados,
- construir filtros más inteligentes,
- comparar datos,
- y resolver problemas más complejos paso a paso.
Una consulta dentro de otra
Ejemplo
Queremos encontrar productos cuyo precio sea mayor al precio promedio.
Consulta
SELECT nombre, precio
FROM productos
WHERE precio > (
SELECT AVG(precio)
FROM productos
);
¿Qué está pasando?
Primero SQL ejecuta:
SELECT AVG(precio)
FROM productos;
Supongamos que el promedio es:
| avg |
|---|
| 546.5 |
Luego utiliza ese resultado dentro de la consulta principal.
Resultado final
| nombre | precio |
|---|---|
| Mouse Gamer | 599 |
| Teclado Mecánico | 1299 |
Subconsultas con IN
También es posible usar subconsultas como listas dinámicas.
Ejemplo
Clientes que han realizado pedidos
SELECT *
FROM clientes
WHERE id IN (
SELECT cliente_id
FROM pedidos
);
Resultado
| id | nombre |
|---|---|
| 1 | Juan Pérez |
| 2 | Ana López |
¿Por qué es útil?
Porque la lista puede cambiar automáticamente dependiendo de los datos reales.
No necesitamos escribir:
IN (1, 2)
La subconsulta genera esa lista dinámicamente.
EXISTS
EXISTS verifica si una subconsulta devuelve resultados.
Ejemplo
Clientes con al menos un pedido
SELECT nombre
FROM clientes c
WHERE EXISTS (
SELECT 1
FROM pedidos p
WHERE p.cliente_id = c.id
);
Resultado
| nombre |
|---|
| Juan Pérez |
| Ana López |
¿Qué significa SELECT 1?
En este caso:
- no importa el valor exacto,
- solo importa si existe al menos una fila.
Subconsultas en FROM
Una subconsulta también puede funcionar como una tabla temporal.
Ejemplo
Totales por cliente
SELECT *
FROM (
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
) AS resumen;
Resultado
| cliente_id | total_gastado |
|---|---|
| 1 | 2097 |
| 2 | 288 |
¿Por qué usar subconsultas?
Las subconsultas ayudan a:
- dividir problemas complejos,
- reutilizar resultados intermedios,
- construir filtros dinámicos,
- y estructurar consultas más avanzadas.
Muchas veces permiten pensar SQL en pequeños bloques en lugar de resolver todo en una sola consulta gigantesca.
Cómo pensar las subconsultas
Una buena forma de entenderlas es esta:
“Primero resuelve esto…
y luego usa ese resultado aquí”
Ese patrón aparece constantemente en:
- dashboards,
- analytics,
- reporting,
- sistemas administrativos,
- y aplicaciones reales.
10. CTEs: organizando consultas complejas
A medida que las consultas crecen, el SQL también puede empezar a volverse difícil de leer.
Las CTEs ayudan a resolver ese problema.
CTE significa:
Common Table Expression.
Pero la forma más fácil de entenderlas es esta:
una consulta temporal con nombre.
¿Por qué son útiles?
Las CTEs permiten:
- dividir consultas complejas,
- reutilizar resultados intermedios,
- organizar lógica paso a paso,
- y hacer el SQL mucho más legible.
Sintaxis básica
Las CTEs utilizan WITH.
Ejemplo
WITH productos_caros AS (
SELECT *
FROM productos
WHERE precio > 500
)
SELECT *
FROM productos_caros;
¿Qué está pasando?
Primero se crea una consulta temporal llamada:
productos_caros
Después esa consulta puede utilizarse como si fuera una tabla normal.
Resultado
| id | nombre | precio |
|---|---|---|
| 1 | Mouse Gamer | 599 |
| 2 | Teclado Mecánico | 1299 |
Pensar en pasos
Las CTEs son útiles porque permiten resolver problemas en etapas.
En lugar de escribir una consulta enorme y difícil de leer:
todo-en-una-sola-linea.sql
podemos separar el problema en bloques más claros.
Ejemplo práctico
Encontrar clientes que han gastado más de 1000
WITH gasto_clientes AS (
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
)
SELECT *
FROM gasto_clientes
WHERE total_gastado > 1000;
Resultado
| cliente_id | total_gastado |
|---|---|
| 1 | 2097 |
Varias CTEs en una misma consulta
También es posible encadenar múltiples pasos.
Ejemplo
WITH ventas_totales AS (
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
),
clientes_activos AS (
SELECT *
FROM ventas_totales
WHERE total_gastado > 1000
)
SELECT *
FROM clientes_activos;
¿Por qué esto es importante?
Porque las consultas reales suelen crecer mucho.
Las CTEs ayudan a que el SQL:
- sea más fácil de leer,
- más sencillo de mantener,
- y menos propenso a errores.
CTEs vs subconsultas
Muchas veces ambos enfoques pueden resolver el mismo problema.
Pero las CTEs suelen ser más legibles cuando la lógica empieza a crecer.
Subconsulta anidada
SELECT *
FROM (
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
) AS resumen;
Versión con CTE
WITH resumen AS (
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
)
SELECT *
FROM resumen;
Cómo pensar las CTEs
Las CTEs son una especie de puente entre:
- consultas simples,
- y transformación avanzada de datos.
En este punto, SQL ya empieza a parecerse menos a:
“hacer consultas rápidas”
y más a:
“construir pequeños pipelines de información”.
11. Vistas (Views): consultas reutilizables
A medida que las consultas empiezan a crecer, muchas veces necesitamos reutilizar resultados frecuentemente.
Por ejemplo:
- reportes,
- dashboards,
- tablas administrativas,
- rankings,
- resúmenes de ventas.
En lugar de escribir la misma consulta una y otra vez, SQL permite guardar consultas reutilizables mediante:
vistas o
VIEW.
¿Qué es una VIEW?
Una VIEW funciona como una tabla virtual construida a partir de una consulta.
La información no se duplica.
La vista simplemente guarda la lógica de la consulta.
Crear una vista
Ejemplo
CREATE VIEW resumen_clientes AS
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id;
¿Qué hace esta vista?
Guarda una consulta que calcula cuánto ha gastado cada cliente.
Después podremos usarla como si fuera una tabla normal.
Consultar una VIEW
SELECT *
FROM resumen_clientes;
Resultado
| cliente_id | total_gastado |
|---|---|
| 1 | 2097 |
| 2 | 288 |
¿Por qué usar vistas?
Las vistas ayudan a:
- reutilizar consultas,
- simplificar SQL complejo,
- organizar lógica de reporting,
- ocultar complejidad,
- y mantener consultas más limpias.
Ejemplo práctico
Imagina una consulta complicada con:
- JOINs,
- GROUP BY,
- filtros,
- métricas.
En lugar de repetir todo constantemente:
consulta_gigante.sql
podemos encapsularla dentro de una vista.
Views como capas de abstracción
Muchas aplicaciones utilizan vistas como una capa intermedia entre:
- las tablas reales,
- y los reportes o dashboards.
Por ejemplo:
tablas reales
↓
views
↓
dashboard / sistema administrativo
Actualizar una VIEW
Si necesitamos cambiar la lógica:
CREATE OR REPLACE VIEW resumen_clientes AS
SELECT
cliente_id,
COUNT(*) AS total_pedidos,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id;
Resultado actualizado
| cliente_id | total_pedidos | total_gastado |
|---|---|---|
| 1 | 2 | 2097 |
| 2 | 1 | 288 |
¿Las VIEWs almacenan datos?
Normalmente no.
Las vistas ejecutan nuevamente la consulta cada vez que las usamos.
Por eso son:
- ligeras,
- flexibles,
- y fáciles de mantener.
Cómo pensar las VIEWs
Las vistas ayudan a transformar SQL en algo más modular.
En este punto, las consultas ya empiezan a comportarse como piezas reutilizables de un sistema más grande.
Y eso es exactamente lo que ocurre en aplicaciones reales:
- reportes,
- dashboards,
- APIs,
- paneles administrativos,
- y sistemas analíticos suelen construirse sobre consultas reutilizables.
12. Funciones analíticas y rankings
Hasta ahora hemos trabajado con:
- filtros,
- agrupaciones,
- subconsultas,
- y transformaciones generales.
Pero SQL también puede analizar filas en relación con otras filas.
Aquí entran las:
funciones analíticas o window functions.
Son muy utilizadas en:
- dashboards,
- rankings,
- analytics,
- reportes,
- métricas,
- y sistemas de recomendación.
¿Qué tienen de especial?
Las funciones analíticas permiten:
- calcular valores sobre grupos de filas,
- sin perder el detalle original.
Eso las hace diferentes de GROUP BY.
GROUP BY reduce filas
Por ejemplo:
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id;
Resultado
| cliente_id | total_gastado |
|---|---|
| 1 | 2097 |
| 2 | 288 |
Aquí las filas originales desaparecen y quedan resumidas.
Las funciones analíticas conservan filas
Ahora veamos otro enfoque.
ROW_NUMBER()
ROW_NUMBER() asigna un número consecutivo a cada fila.
Ejemplo
SELECT
nombre,
precio,
ROW_NUMBER() OVER (ORDER BY precio DESC) AS posicion
FROM productos;
Resultado
| nombre | precio | posicion |
|---|---|---|
| Teclado Mecánico | 1299 | 1 |
| Mouse Gamer | 599 | 2 |
| Cable USB-C | 199 | 3 |
| Libreta A5 | 89 | 4 |
¿Qué significa OVER()?
OVER() define:
- cómo se organiza la ventana de datos,
- y sobre qué conjunto de filas trabajará la función analítica.
RANK()
RANK() funciona parecido a ROW_NUMBER(), pero respeta empates.
Ejemplo
SELECT
nombre,
precio,
RANK() OVER (ORDER BY precio DESC) AS ranking
FROM productos;
DENSE_RANK()
DENSE_RANK() también maneja empates, pero sin saltar posiciones.
PARTITION BY
PARTITION BY divide los datos en grupos independientes.
Es parecido a un GROUP BY, pero sin colapsar filas.
Ejemplo
Ranking por categoría
SELECT
nombre,
categoria_id,
precio,
ROW_NUMBER() OVER (
PARTITION BY categoria_id
ORDER BY precio DESC
) AS posicion
FROM productos;
Resultado conceptual
| nombre | categoria_id | precio | posicion |
|---|---|---|---|
| Teclado Mecánico | 1 | 1299 | 1 |
| Mouse Gamer | 1 | 599 | 2 |
| Libreta A5 | 2 | 89 | 1 |
| Cable USB-C | 3 | 199 | 1 |
LAG()
LAG() permite acceder a filas anteriores.
Esto es muy útil para:
- tendencias,
- comparaciones temporales,
- métricas históricas,
- análisis de cambios.
Ejemplo conceptual
SELECT
fecha,
total,
LAG(total) OVER (ORDER BY fecha) AS venta_anterior
FROM pedidos;
Resultado conceptual
| fecha | total | venta_anterior |
|---|---|---|
| 2026-05-01 | 1898 | NULL |
| 2026-05-02 | 288 | 1898 |
| 2026-05-04 | 199 | 288 |
¿Dónde aparecen estas funciones?
Las funciones analíticas son extremadamente comunes en:
| Caso | Ejemplo |
|---|---|
| Rankings | Productos más vendidos |
| Analytics | Ventas por periodo |
| Dashboards | Top clientes |
| Ecommerce | Productos destacados |
| Finanzas | Comparaciones históricas |
| Redes sociales | Rankings de actividad |
Cómo pensar esta sección
En este punto, SQL ya puede:
- almacenar información,
- relacionar tablas,
- transformar datos,
- resumir métricas,
- y analizar comportamiento.
Aquí SQL deja de sentirse únicamente como:
“consultar datos”
y empieza a parecerse más a:
“hacer análisis sobre información real”.
13. SQL en aplicaciones reales
Hasta ahora vimos:
- cómo almacenar datos,
- relacionar tablas,
- filtrar información,
- agrupar resultados,
- construir reportes,
- y analizar datos.
Pero… ¿dónde aparece realmente todo esto?
La respuesta corta es:
prácticamente en todos lados.
Ecommerce
Los ecommerce utilizan SQL constantemente para manejar:
- productos,
- clientes,
- pedidos,
- inventario,
- pagos,
- envíos,
- carritos,
- cupones,
- y reportes de ventas.
Ejemplo
Productos más vendidos
SELECT
producto_id,
SUM(cantidad) AS vendidos
FROM detalle_pedido
GROUP BY producto_id
ORDER BY vendidos DESC;
También se usa para:
- buscar productos,
- paginar catálogos,
- mostrar historial de compras,
- calcular stock,
- generar dashboards administrativos.
Analytics y dashboards
SQL es una de las herramientas más importantes del mundo analítico.
Se utiliza para:
- métricas,
- KPIs,
- tendencias,
- rankings,
- cohortes,
- y reporting.
Ejemplo
Ventas por mes
SELECT
DATE_TRUNC('month', fecha) AS mes,
SUM(total) AS ventas
FROM pedidos
GROUP BY mes
ORDER BY mes;
Ejemplo
Top clientes
SELECT
cliente_id,
SUM(total) AS total_gastado
FROM pedidos
GROUP BY cliente_id
ORDER BY total_gastado DESC;
Redes sociales
Las redes sociales también funcionan sobre bases de datos relacionales.
SQL ayuda a manejar:
- usuarios,
- publicaciones,
- comentarios,
- follows,
- likes,
- mensajes,
- notificaciones.
Ejemplo conceptual
Usuarios con más seguidores
SELECT
usuario_id,
COUNT(*) AS seguidores
FROM follows
GROUP BY usuario_id
ORDER BY seguidores DESC;
Sistemas ERP y administrativos
ERPs y sistemas empresariales utilizan SQL para:
- facturación,
- almacenes,
- compras,
- inventarios,
- auditoría,
- logística,
- proveedores,
- cuentas por cobrar,
- y reportes operativos.
Ejemplo
Inventario bajo
SELECT *
FROM productos
WHERE stock < 5;
Apps móviles y plataformas modernas
Muchas aplicaciones móviles también dependen de SQL detrás de escena.
Por ejemplo:
- perfiles,
- historial,
- preferencias,
- sesiones,
- actividad,
- configuraciones,
- contenido guardado.
Ejemplo
Historial reciente
SELECT *
FROM historial
WHERE usuario_id = 15
ORDER BY fecha DESC
LIMIT 10;
Lo importante no es memorizar comandos
La meta principal de esta guía no es memorizar sintaxis.
Es desarrollar intuición.
Porque una vez entiendes cómo pensar en:
- tablas,
- relaciones,
- filtros,
- agrupaciones,
- y transformación de datos,
muchos problemas reales empiezan a sentirse familiares aunque cambie el contexto.
Qué sigue después de esta guía
SQL tiene muchísimo más por explorar.
Algunos temas importantes que normalmente aparecen después son:
| Tema | ¿Para qué sirve? |
|---|---|
| Índices | Acelerar consultas |
| Performance | Optimizar queries lentas |
| Transacciones | Garantizar consistencia |
| PostgreSQL avanzado | Features más potentes |
| JSON y JSONB | Datos semiestructurados |
| Full Text Search (FTS) | Motores de búsqueda |
| ETL | Transformación de datos |
| Business Intelligence (BI) | Dashboards y analytics |
| Tuning | Optimización avanzada |
El verdadero aprendizaje empieza construyendo cosas
SQL se aprende mucho más rápido cuando empieza a utilizarse en proyectos reales.
Puede ser:
- una app,
- un dashboard,
- un sistema administrativo,
- un ecommerce,
- un ERP,
- o incluso reemplazar procesos complejos de Excel.
Porque al final, SQL no trata únicamente de bases de datos.
Trata sobre:
organizar, conectar y entender información.